每一次调用大模型,对底层引擎来说都是孤立的一次计算,模型自己不会在内部存任何对话历史。你跟它聊了十句话,它能接得上,靠的不是它”记住了”,而是应用层老老实实把前面十句话又喂了一遍。
这套机制在双轮问答里几乎不会出毛病。麻烦出在 Agent 开始自己调用工具、自己规划任务之后。对话不再是简单的一问一答,而是夹杂着工具调用请求、工具返回结果、模型的中间推理,一来二去轮次拉长,历史记录跟着膨胀。模型的上下文窗口是有硬上限的,按 Token 计费的账单也跟着水涨船高。
现有 ChatMemory 的缺点
Spring AI ChatMemory 目前最常用的实现是 MessageWindowChatMemory,逻辑很朴素:维护一个固定大小的消息窗口(默认最近 20 条),超了就把最老的几条砍掉,顺手把最初的 SystemMessage 焊死不动。
这套方案的问题是,它砍消息的时候完全不知道自己在砍什么。
一次完整的工具调用,通常要拆成四条消息:用户提问、模型发起的工具调用请求、工具执行完返回的结果、模型综合结果给出的最终回复。如果滑动窗口的截断点恰好落在这四条中间,比如把用户提问和工具调用请求都砍掉了,只剩工具结果和最终回复,模型下一次推理时看到的就是一截没头没尾的工具返回值。对严格校验消息时序的模型来说,这种残缺上下文很容易诱发奇怪的输出,甚至直接报协议错误。
持久化这条线上也有缺口。生产环境常用的 JdbcChatMemoryRepository,数据模型设计得偏早期,只认用户提问和模型纯文本回复这两种消息。一旦开了 Function Calling,工具调用消息和工具响应就没法存进数据库。应用重启或者扩容之后,从数据库里重新加载出来的历史,工具调用的痕迹会凭空消失。模型不再知道自己刚才是靠查了什么数据得出的结论。
再加上 Spring AI 2.0 把工具调用循环搬进了 Advisor 链做递归处理,老的记忆机制卡在这套新架构里也有点水土不服:放在循环外层,只能存最终对话摘要,中间的推理痕迹全丢;硬塞进循环内层,又会因为 JDBC 不认工具消息而直接抛异常。
说白了,滑动窗口这套方案对付十轮以内的简单问答完全够用,一旦 Agent 开始频繁调用工具、跑长流程,它的设计假设就站不住了。
Spring AI Session 重构
1 | <dependency> |
Spring AI Session 解决这个问题的思路,是先换一个记账方式。
它不再把对话历史当成一个可以随意增删的扁平消息列表,而是拆成两层结构。Session 是个不可变的元数据对象,只存会话 ID、用户 ID、TTL 这些轻量信息,本身不背消息负载。真正的内容放在 SessionEvent 里:每一条用户输入、模型回复、工具调用、工具结果,都被包装成一个带 UUID、时间戳、所属 sessionId 的不可变事件,按时间顺序只追加、不修改。
这套结构本身不算新鲜,事件溯源在别的领域早就是成熟套路。Session 真正有意思的地方,是它在这套日志之上定义了一个叫”轮次”(Turn)的概念,把它当成压缩和截断操作的最小单位。
一个 Turn 严格从一条 UserMessage 开始,把它后面所有级联产生的事件(工具调用、工具结果、中间推理、最终回复)都算作同一个 Turn,直到下一条 UserMessage 出现才算结束。
这个设计带来的直接好处是:不管用什么策略裁剪历史,裁剪点永远落在 Turn 的边界上,不会再把一次完整的工具调用拦腰截断。模型要么看到一个完整的轮次,要么这个轮次完全不在窗口里,不存在”看到一半”这种状态。
Session 自动压缩
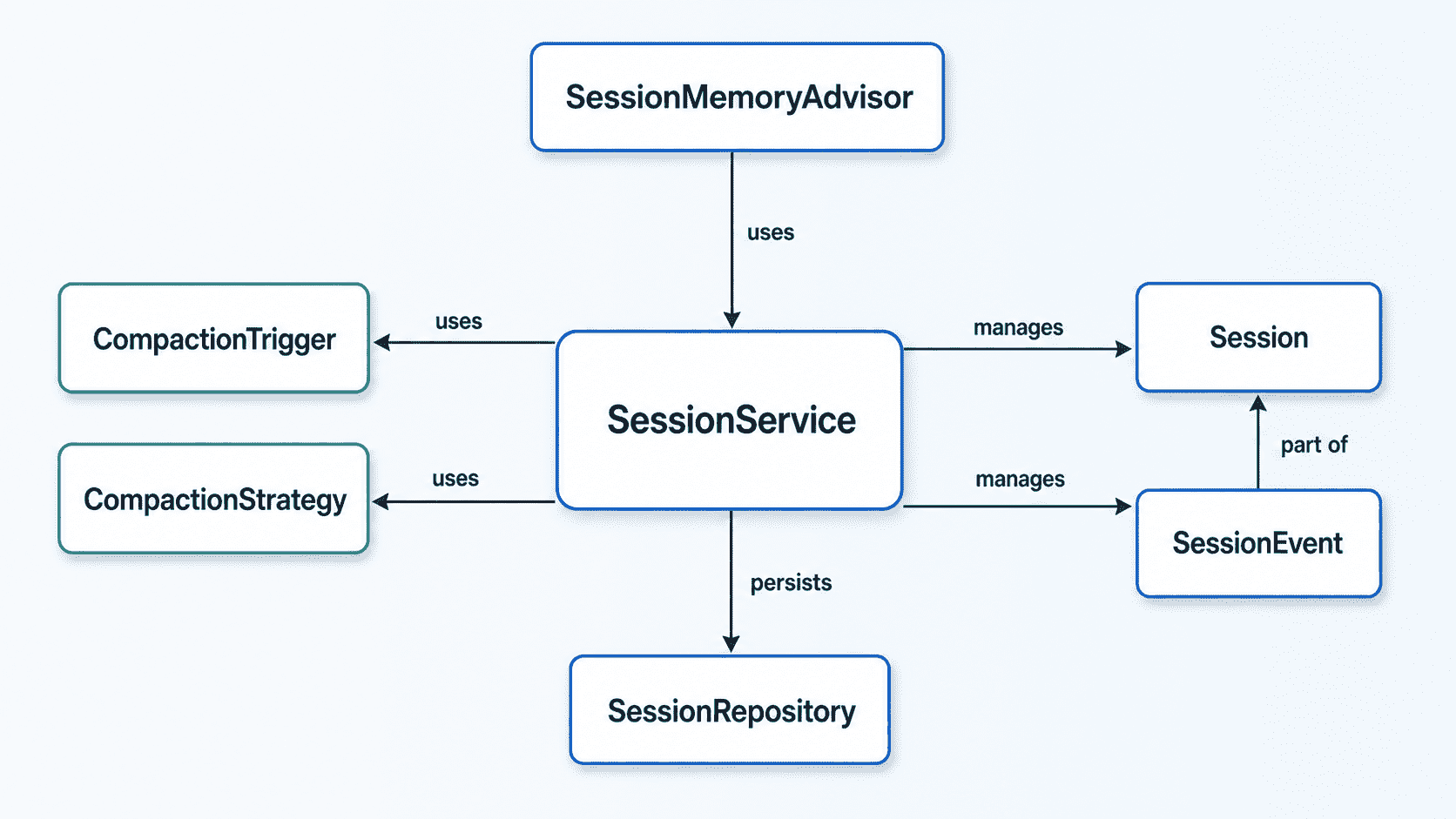
光有 Turn 边界还不够,什么时候该压缩、压缩时具体留什么扔什么,Session 把这两件事拆成了触发器(Trigger)和策略(Strategy)两个独立的组件,可以自由组合。
触发器负责判断”现在该不该出手”:
TurnCountTrigger:轮次数超过设定值就触发,比如 20 轮。TokenCountTrigger:按预估 Token 消耗量触发,对成本敏感的场景更合适。CompositeCompactionTrigger:把多个条件组合成 OR/AND 逻辑,比如轮次数或 Token 数任一超标就动手。
策略负责回答”具体怎么裁”:
| 策略 | 要不要调用模型 | 怎么干 |
|---|---|---|
| SlidingWindowCompactionStrategy | 不需要 | 按事件数硬截,截断点对齐到最近的 Turn 边界 |
| TurnWindowCompactionStrategy | 不需要 | 完整保留最近 N 个轮次,一个轮次内不管有多少次工具重试都整体留下或整体丢弃 |
| TokenCountCompactionStrategy | 不需要 | 按 Token 预算自底向上累加轮次,直到下一轮会超预算为止 |
| RecursiveSummarizationCompactionStrategy | 需要 | 把要归档的轮次交给模型总结成一对”合成的”用户+助手消息,拼到窗口最前面,每次压缩都在上一次摘要基础上滚动叠加 |
接入也不复杂,用 SessionMemoryAdvisor 替换掉原来的 MessageChatMemoryAdvisor 就行:
1 | SessionMemoryAdvisor advisor = SessionMemoryAdvisor.builder(sessionService) |
调用时传个 session ID,会话不存在会自动创建。历史加载、消息追加、触发压缩,这套流程全在 Advisor 内部完成,业务代码基本不用关心。
多 Agent 支持
现在的 Agent 应用越来越喜欢把一个大任务拆给好几个子 Agent 并行处理。如果它们共享同一份线性对话日志,彼此的中间推理会搅在一起,谁的上下文里都是一堆跟自己无关的噪音。
Session 用一个叫 Branch 的标签解决这个问题。SessionEvent 上可以挂一个点分隔的分支路径,比如 orch.researcher,配合 EventFilter.forBranch(...) 装进 Advisor,每个子 Agent 就只能看到自己和”祖先”产生的事件,互相隐身。压缩生成的摘要事件永远挂在根分支上,所有 Agent 都看得到。这个细节我觉得设计得挺细,既隔离了噪音,又没把共识性的总结藏起来。
另外,压缩这件事砍掉的只是喂给模型的那部分上下文,原始事件日志一条不少地留在持久化层。SessionEventTools 把这层日志包装成一个叫 conversation_search 的工具,挂给模型之后,遇到被压缩掉的细节,模型可以自己发起关键词搜索去翻旧账,而不是干瞪眼装作什么都没发生过。
总结
按 Spring AI 的路线图,预计会在 2.1 版本里正式取代 ChatMemory,时间窗口大概在 2026 年 11 月前后。