为什么不能使用现有框架?
官方 R1 模型的特殊性
虽然目前网上有许多教程介绍如何通过 Spring AI 或 LangChain4j 的 OpenAI 适配器来接入 DeepSeek,但这种方式存在以下关键问题:-
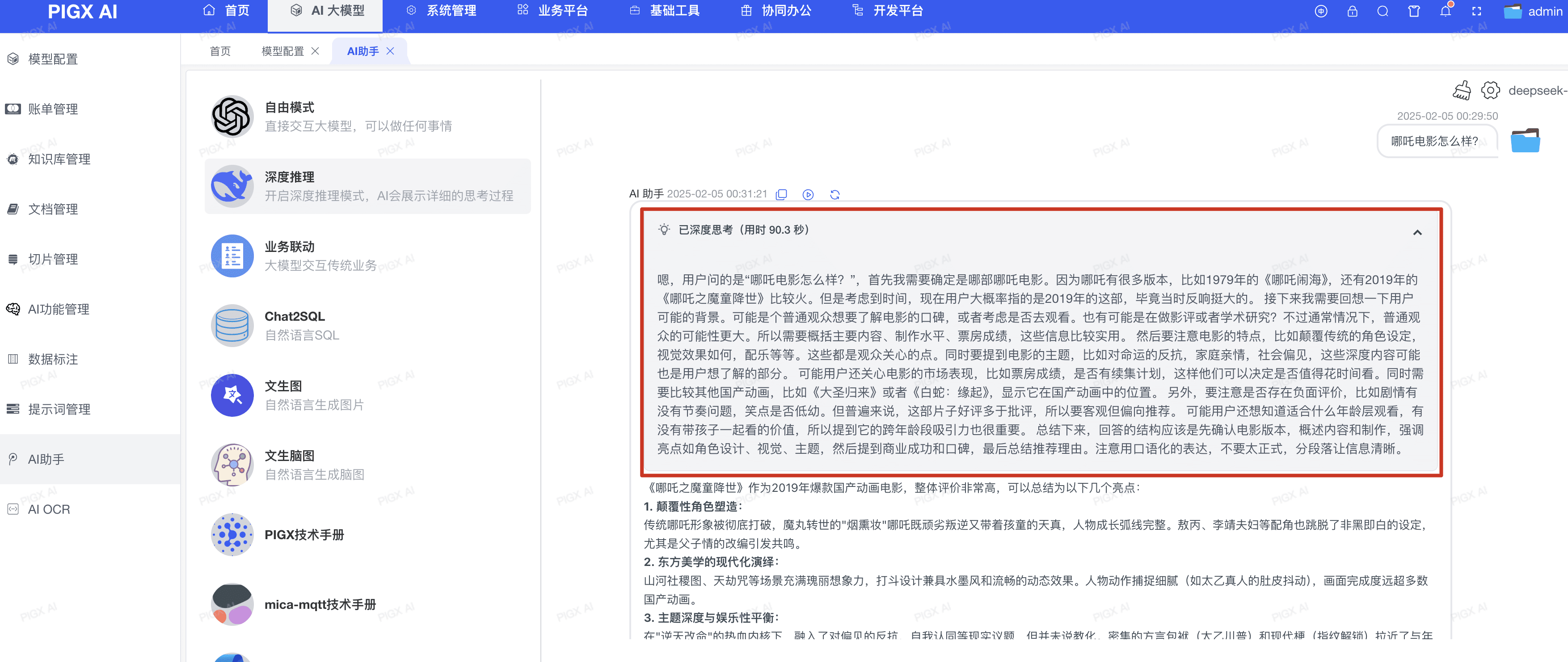
思维链内容丢失:R1 模型最核心的特性是提供详细的推理过程,这些内容包含在特殊的
reasoning_content字段中,现有框架会完全忽略这个关键信息 - 响应模式的改变:R1 模型强依赖流式输出,其推理过程与通用文本大模型不同 - 会先输出详细的思考过程,再给出最终推理结果。这种”思考在前、结论在后”的模式导致整个响应时间较长,因此必须采用流式输出和专门的思维链展示交互,否则用户体验会大打折扣
-
参数限制:R1 模型对以下参数有特殊要求:
- temperature、top_p、presence_penalty、frequency_penalty:虽然可以设置但不会生效
- logprobs、top_logprobs:设置会导致API调用失败
 框架适配现状
目前主流的 AI 框架都未对 DeepSeek R1 进行官方适配:
框架适配现状
目前主流的 AI 框架都未对 DeepSeek R1 进行官方适配:
- LangChain4j:暂无计划支持 DeepSeek 特有的思维链功能
- Spring AI:当前版本仅支持标准的 OpenAI 协议,无法处理 R1 的特殊响应格式
Ollama 部署的特殊处理
当使用 Ollama 私有化部署 R1 时,情况略有不同:<think> 标签包装后通过 content 字段输出。这种方式虽然保证了兼容性,但在多轮对话中会产生额外的 token 开销。
 建议在前端实现以下处理逻辑来提取思维链内容:
建议在前端实现以下处理逻辑来提取思维链内容:
基于 Spring WebFlux 的实现方案
虽然 Spring AI 和 LangChain4j 提供了便捷的 AI 集成方案,但对于 DeepSeek R1 这样的特殊模型,直接调用 API 是更好的选择。使用 Spring WebFlux 不仅可以完整获取思维链内容,还能通过其异步非阻塞特性提供更好的性能表现。基于 Spring WebFlux 的优雅实现
为了充分利用 R1 模型的特性,我们可以使用 Spring WebFlux 实现一个直接调用 API 的解决方案。这不仅能完整保留思维链内容,还能通过响应式编程提供更好的性能。 在处理 AI 模型 API 调用时,WebFlux 相比传统的阻塞式 HTTP 客户端有以下优势:-
非阻塞 I/O
- 使用 Netty 作为底层实现,支持异步非阻塞的网络操作
- 不会因为长时间的 API 调用而阻塞线程池
- 能更高效地处理大量并发请求
-
响应式流
- 通过 SpringBoot WebClient 的声明式 API 简化调用流程
- 简化 Server-Sent Events (SSE) 开发,实现实时数据推送
- 方便实现流式输出的 UI 交互
API 实现
响应解析
总结
通过本文提供的实现方案,我们可以:- 完整保留 R1 模型的思维链能力
- 利用 WebFlux 实现高性能的流式处理