gpt-oss。更棒的是,为了让广大开发者能够轻松在本地环境中使用这些模型,OpenAI 与广受欢迎的本地大模型运行框架 Ollama 展开了深度合作。
现在,只需要一条命令,就可以在自己的电脑上运行拥有强大推理能力和代理(Agent)功能的 gpt-oss 模型。无论是想进行本地开发、功能测试,还是希望拥有一个不受网络限制的私有AI助手,这都将是一个绝佳的选择。
gpt-oss 模型概览
此次 OpenAI 推出了两个不同规模的模型,以满足不同场景的需求:gpt-oss-20b:一个200亿参数的模型,专为低延迟、本地化或特定领域的应用场景设计。它在速度和性能之间取得了很好的平衡,非常适合在个人电脑上运行。gpt-oss-120b:一个1200亿参数的旗舰模型,为生产环境、通用目的和高强度推理任务而生。它能提供顶级的性能,适合在配备专业级GPU的服务器上部署。
核心特性
gpt-oss 不仅仅是一个聊天机器人,它还内置了一系列强大的“代理”功能。
- 代理能力(Agentic Capabilities):模型原生支持函数调用(Function Calling)、网络浏览(Web Browsing)、生成结构化输出(如JSON)。Ollama 还为其提供了可选的内置网络搜索功能,让模型能够获取最新信息。
- 完整的思维链(Full Chain-of-Thought):模型完整的推理过程都是可访问的,这极大地简化了调试,并提升了结果的可信度。
- 可配置的推理级别(Configurable Reasoning Effort):可以根据应用场景对速度和细节的需求,轻松调整模型的推理级别(低、中、高)。
- 可微调(Fine-tunable):开发者可以根据自己的特定需求,通过参数微调来完全定制模型。
- 友好的 Apache 2.0 许可证:这意味着可以自由地进行构建、测试、个性化和商业部署,没有版权限制或专利风险。

技术揭秘:MXFP4 量化
为了让这些庞大的模型能够在消费级硬件上运行,OpenAI 采用了一种名为MXFP4 的量化技术。
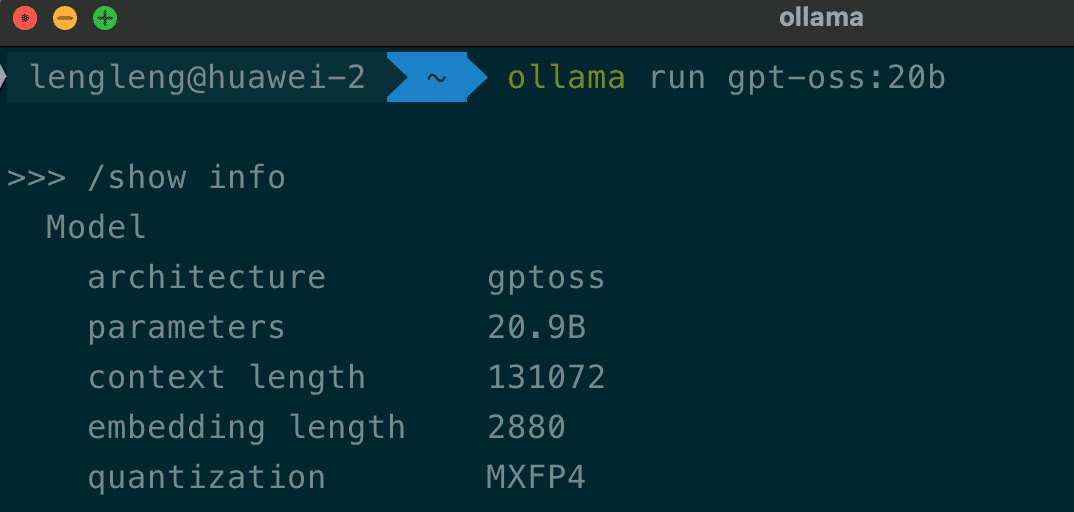
模型中超过90%的参数来自于专家混合(MoE)层的权重。通过将这些权重进行训练后量化到 MXFP4 格式(每个参数约4.25位),模型的内存占用被大幅降低。这使得 gpt-oss-20b 模型能够在仅有16GB内存的系统上流畅运行,而 gpt-oss-120b 模型也足以装入单个80GB的GPU中。
Ollama 框架原生支持 MXFP4 格式,无需额外的量化或转换,并与 OpenAI 的参考实现进行了基准测试,以确保相同的输出质量。
快速上手指南
得益于 Ollama 的便捷性,在本地运行gpt-oss 只需两步。
第一步:安装 Ollama
访问 Ollama 官网,下载并安装适用于相应操作系统(macOS, Windows, Linux)的最新版本。 安装完成后,在 macOS 上,可以在菜单栏看到 Ollama 的图标。在终端(或 Windows 的 CMD/PowerShell)中,可以通过运行ollama 命令来验证安装是否成功。
重要提醒:如果已经安装过 Ollama,请务必升级到最新版本以确保对 gpt-oss 模型的完整支持。可以通过重新下载安装包或使用包管理器来更新。
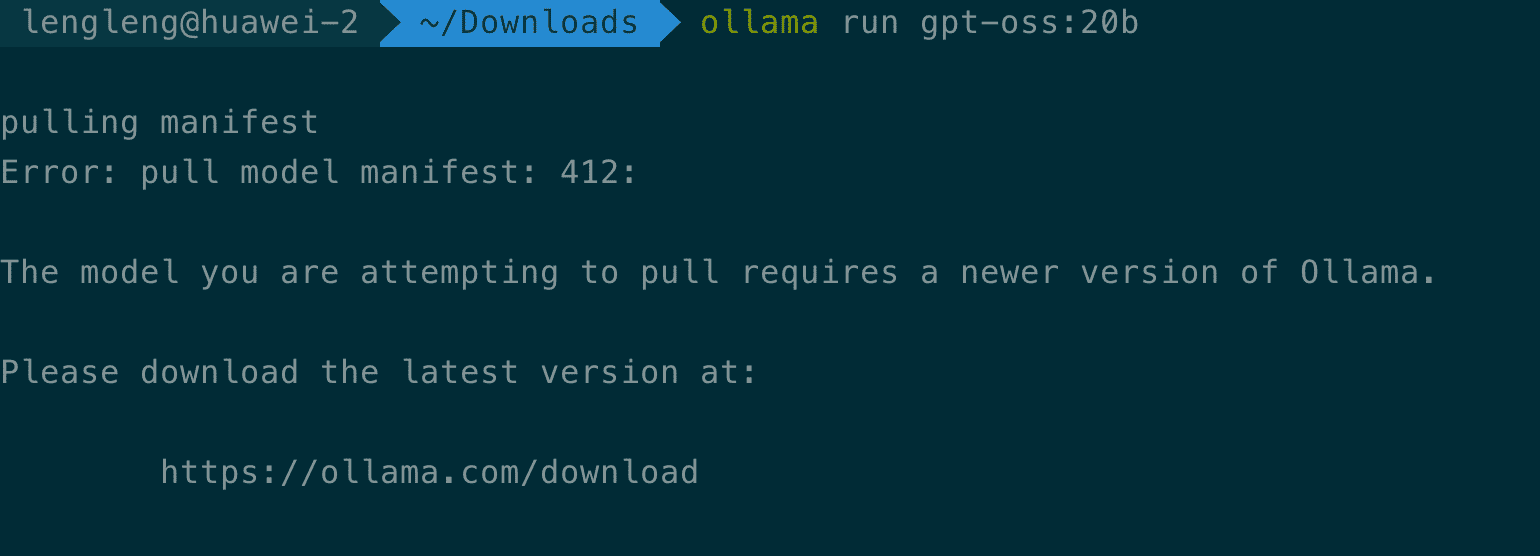
第二步:运行 gpt-oss 模型
打开终端,输入以下命令即可下载并运行gpt-oss-20b 模型:
多种方式与模型交互
1. 命令行工具
运行ollama run 命令后,可以直接在终端提问。还可以使用一些内置命令来获取模型信息:
2. 使用 cURL 调用 API
Ollama 会在本地11434 端口启动一个HTTP服务。可以像调用任何REST API一样与模型交互:
3. 使用 Java 代码
通过spring-ai-ollama 库,可以轻松地将 gpt-oss 集成到 Java 应用中。
首先,安装库:
gpt-oss 的推理级别参数。如果需要使用推理功能,可以考虑直接通过 HTTP API 调用的方式来设置相关参数。