背景
RAG 文本切片
文本切片是构建高效RAG(检索增强生成)系统的关键预处理步骤:- 首先,语言模型的上下文窗口限制要求将长文本切分为语义完整的段落,确保关键信息能被完整捕获;
- 其次,精准的切片策略能提升向量检索的查准率,避免因信息过载导致的语义稀释问题;
- 最后,合理的切片粒度(如句子或段落级)可保持语义连贯性,为后续的上下文推理奠定基础。
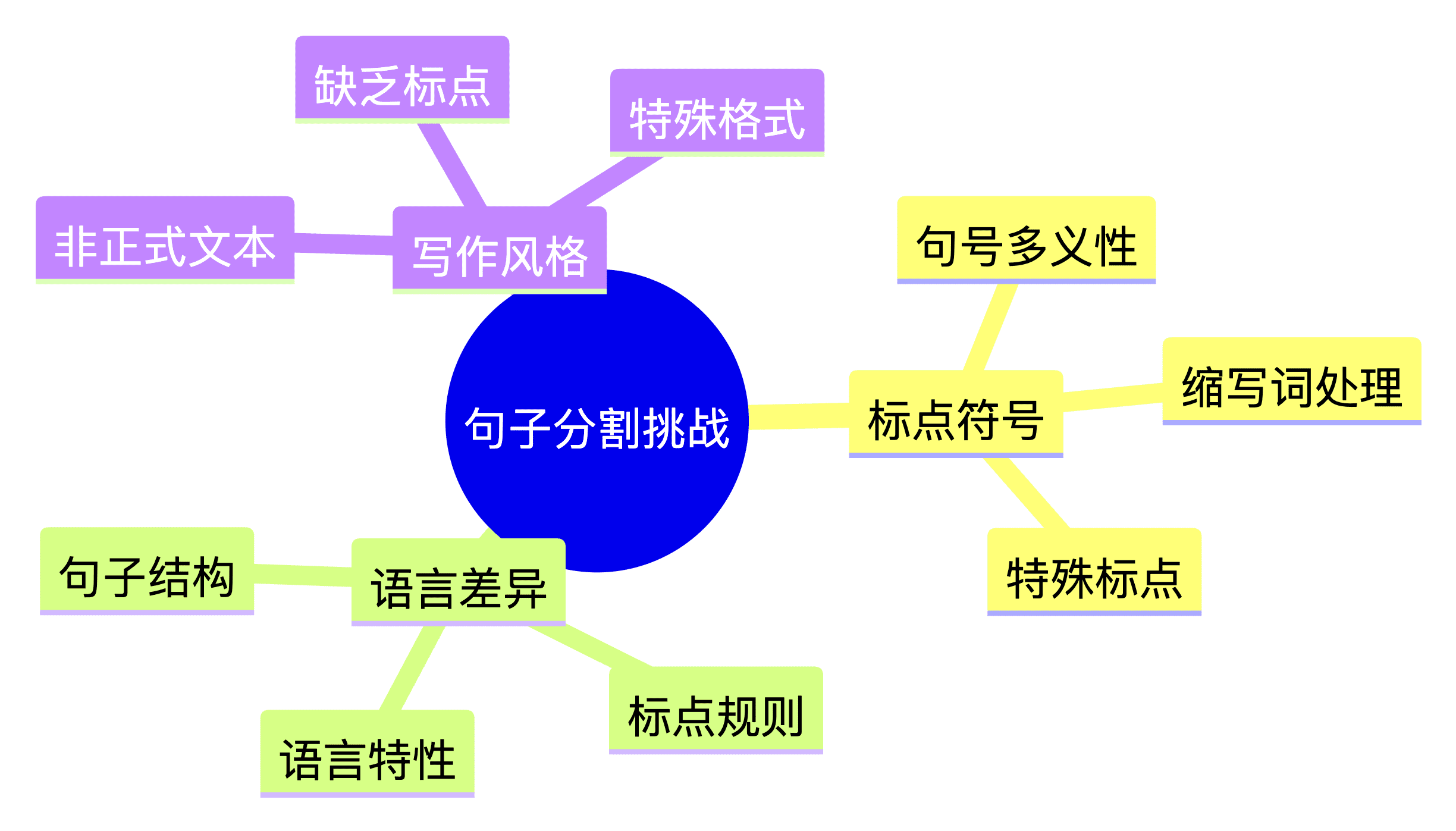
切片常见问题
在实际应用中,文本分割面临以下核心挑战:- 语义边界模糊:自然语言中句号的多重语义(如缩写词、小数点)导致简单的标点分割不可靠
- 语言特定处理:中文无空格分词、日文无明确句尾等语言特性需要专门处理逻辑
- 领域术语干扰:医疗缩写(如”q.d.”)、法律条款编号等专业符号易被误判为句子结尾
- 格式噪声干扰:源代码片段、数学公式等非自然语言内容需要特殊过滤机制
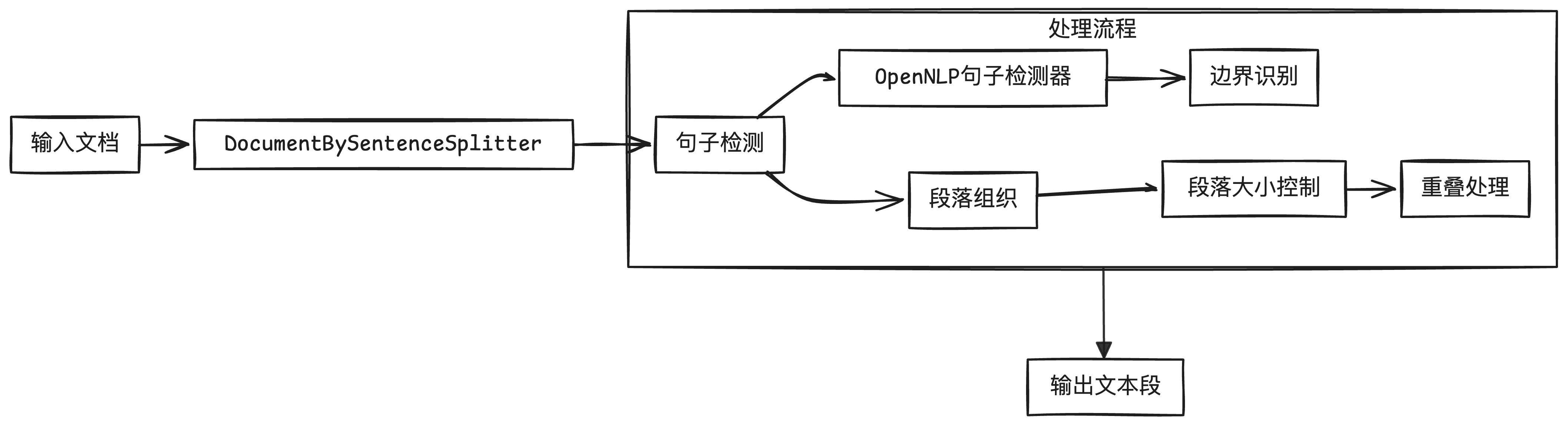
解决方案
DocumentBySentenceSplitter 是 langchain4j 库中的一个重要组件,它能够将文档智能地分割成句子,并生成适合后续处理的文本段。本文将详细介绍这个组件如何利用 Apache OpenNLP 的句子检测功能来实现文本分割。
什么是 OpenNLP
Apache OpenNLP 是一个强大的自然语言处理工具包,它基于机器学习技术,能够高效处理包括句子检测在内的多种 NLP 任务。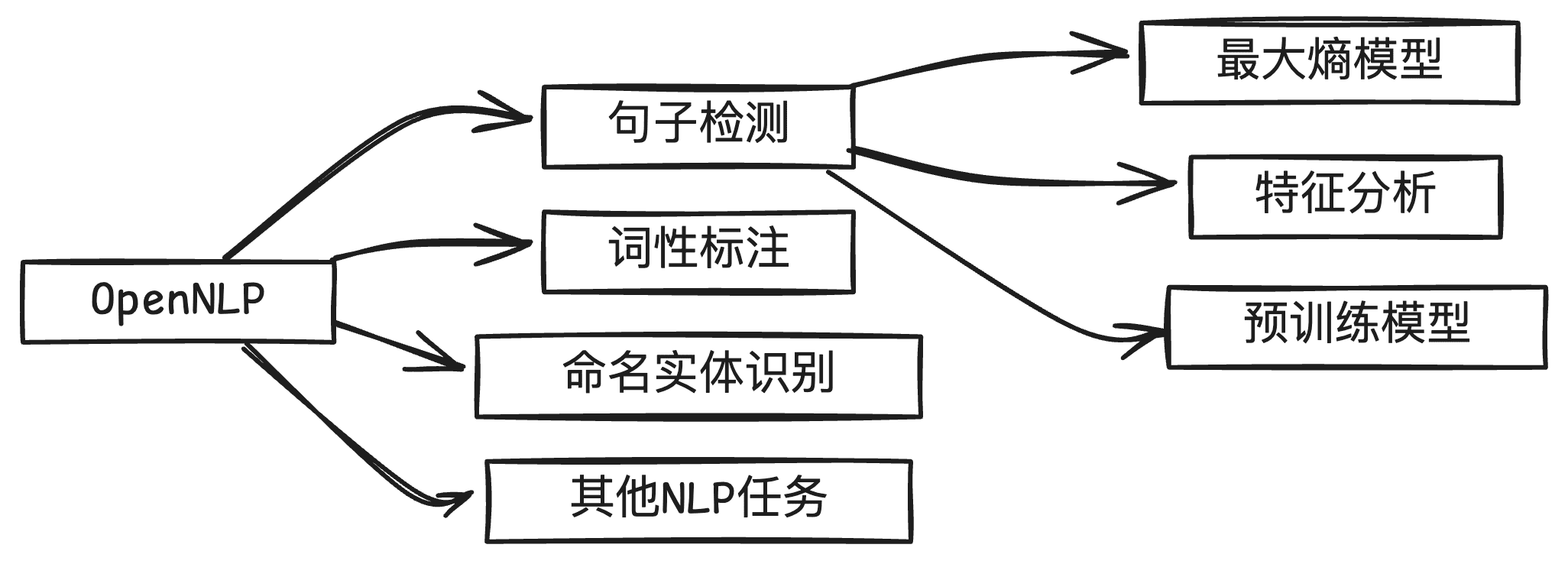
代码示例
总结
当前 langchain4j 基于 OpenNLP 提供了开箱即用的句子分割实现,默认加载英文方言的句子分割模型。这为文本切片提供了良好的基础功能,但在实际应用中我们可以进一步扩展和优化:- 自定义模型训练:可以基于特定领域语料训练自己的 OpenNLP 模型,以提升特定场景下的分割准确率
-
扩展中文 NLP 工具集成:
- 可以参考当前实现思路,集成主流中文 NLP 工具,如: HanLP、jieba 这些工具都有较好的中文语义理解能力,能更好地处理中文文本的语义边界