DeepSeek R1 凭借其强大的思维链能力在开发者中广受欢迎,但 Spring AI 等主流框架对其支持不足,特别是在思维链内容保留和流式输出方面存在诸多限制。deepseek4j 1.4 版本重磅发布,带来联网搜索、多渠道支持等重要更新。
背景
deepseek4j提供了一套强大的 API,涵盖了 Reasoner、Function Calling、JSON 解析等特性。本工具旨在简化 DeepSeek API 的集成,让开发者能够快速调用相关能力并集成到自己的应用中。 然而,DeepSeek 官方并未提供向量模型,因此本工具在最初设计时未考虑向量搜索的集成。现状
- deepseek4j 已全面支持 DeepSeek 的 Reasoner、Function Calling、JSON 解析等功能。
- R1 模型的私有知识库需求正在增长,许多开发者希望在 DeepSeek 之上实现私有知识库。
- 零额外依赖:无需引入新的依赖包,保持框架轻量
- 完美兼容性:与现有架构无缝衔接,确保向后兼容
- 标准化接入:采用业界通用的 OpenAI 协议,降低学习成本
快速上手
本文章将带领大家从零开始构建一个基础 RAG 系统。通过白盒编码的方式,不仅能深入理解 RAG 的核心原理,还可以根据实际需求灵活调整和优化各个环节。相比直接使用现有的开源 RAG 产品,这种方式能让我们更好地掌控系统行为,实现更精准的知识检索和问答效果。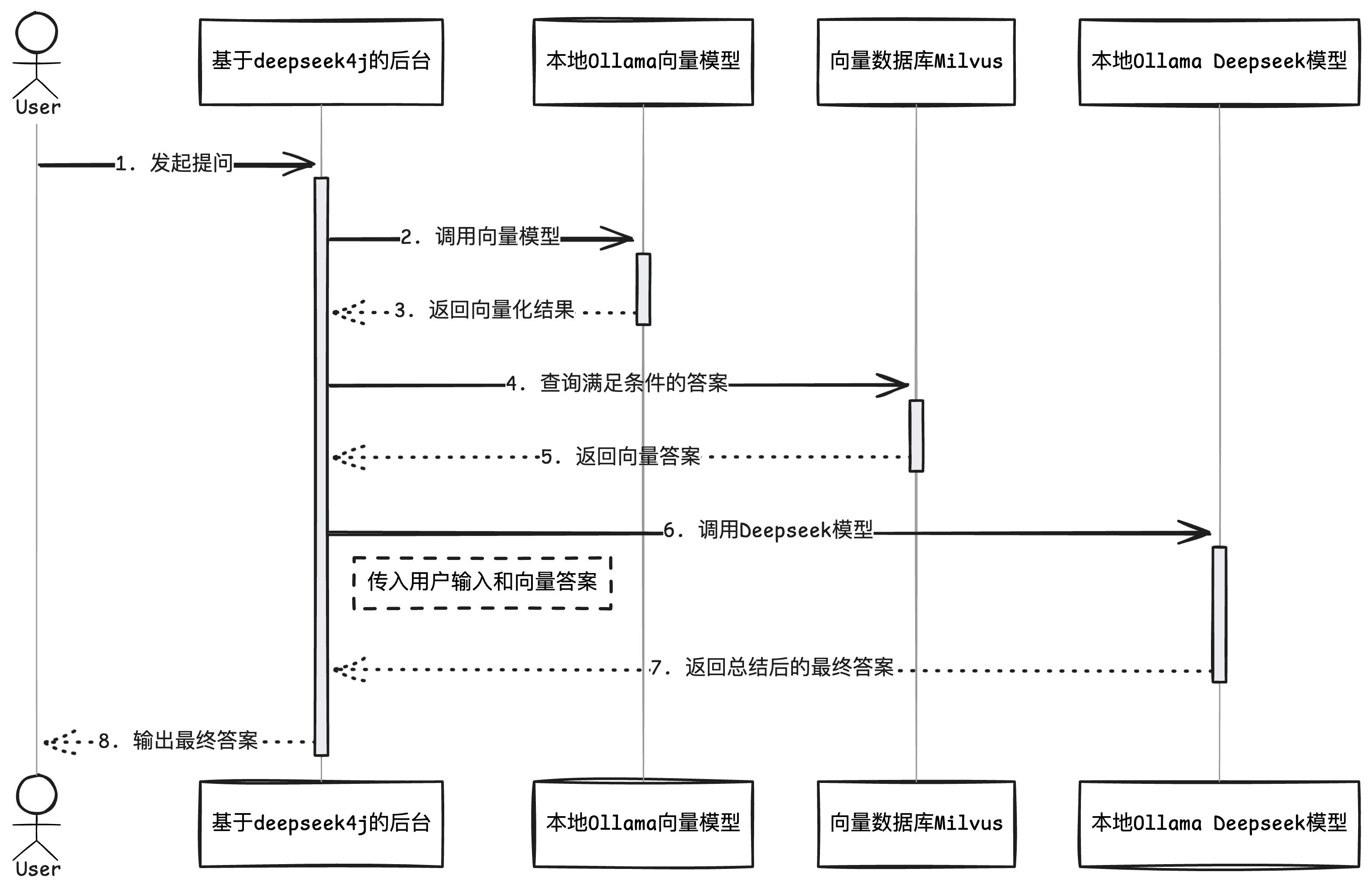
1. 环境准备
在开始构建 RAG 系统之前,我们需要准备以下环境:1.1 Ollama 模型准备
首先安装 Ollama,然后下载以下必要的模型:1.2 向量数据库准备
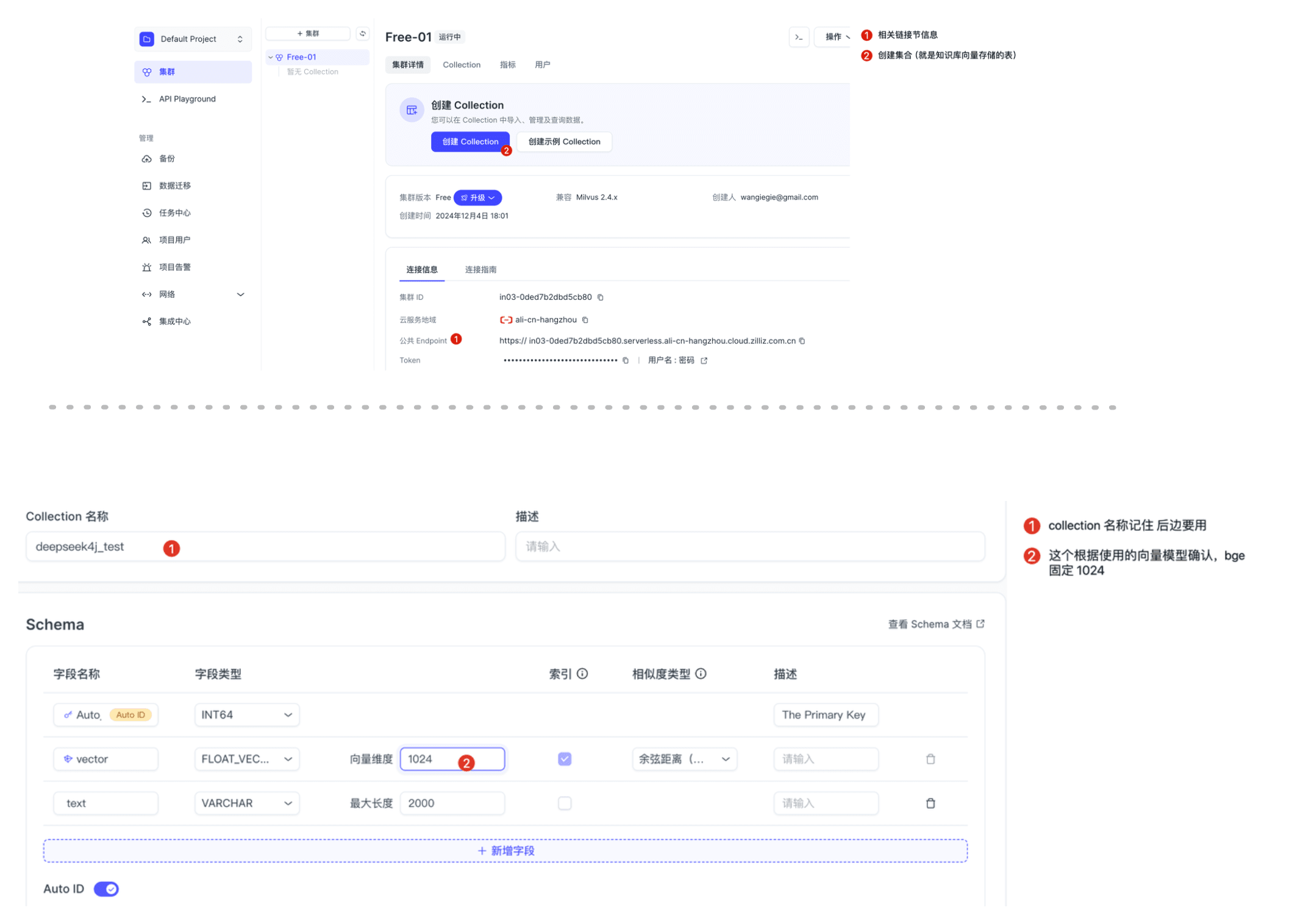
本文使用 Milvus 作为向量数据库,你可以选择以下两种方式之一进行安装: 方式一:使用milvus 测试环境- 访问 Zilliz Cloud 中文版:https://cloud.zilliz.com.cn
- 获取连接信息(后续配置需要用到)
注意:如果选择 Docker 安装方式,请确保你的网络环境能够正常访问 Github。
- 初始化向量数据:创建本次知识库存储、获取链接信息和表信息:
1.3 项目依赖
在你的 Maven 项目中添加以下依赖:application.yml 配置
2. 初始化私有知识
在构建 RAG 系统时,第一步是将已有的知识内容转换为向量形式并存储到向量数据库中。2.1 创建链接 链接客户端
2.2 准备资料并向量化上传
以下示例演示如何处理文本资料。对于 Office 文档、图片、PDF、音视频等其他格式的文件处理,deepseek4j 提供了完整的解决方案,详细使用方法请参考官方文档: https://javaai.pig4cloud.com/deepseek。3. 创建 RAG 接口
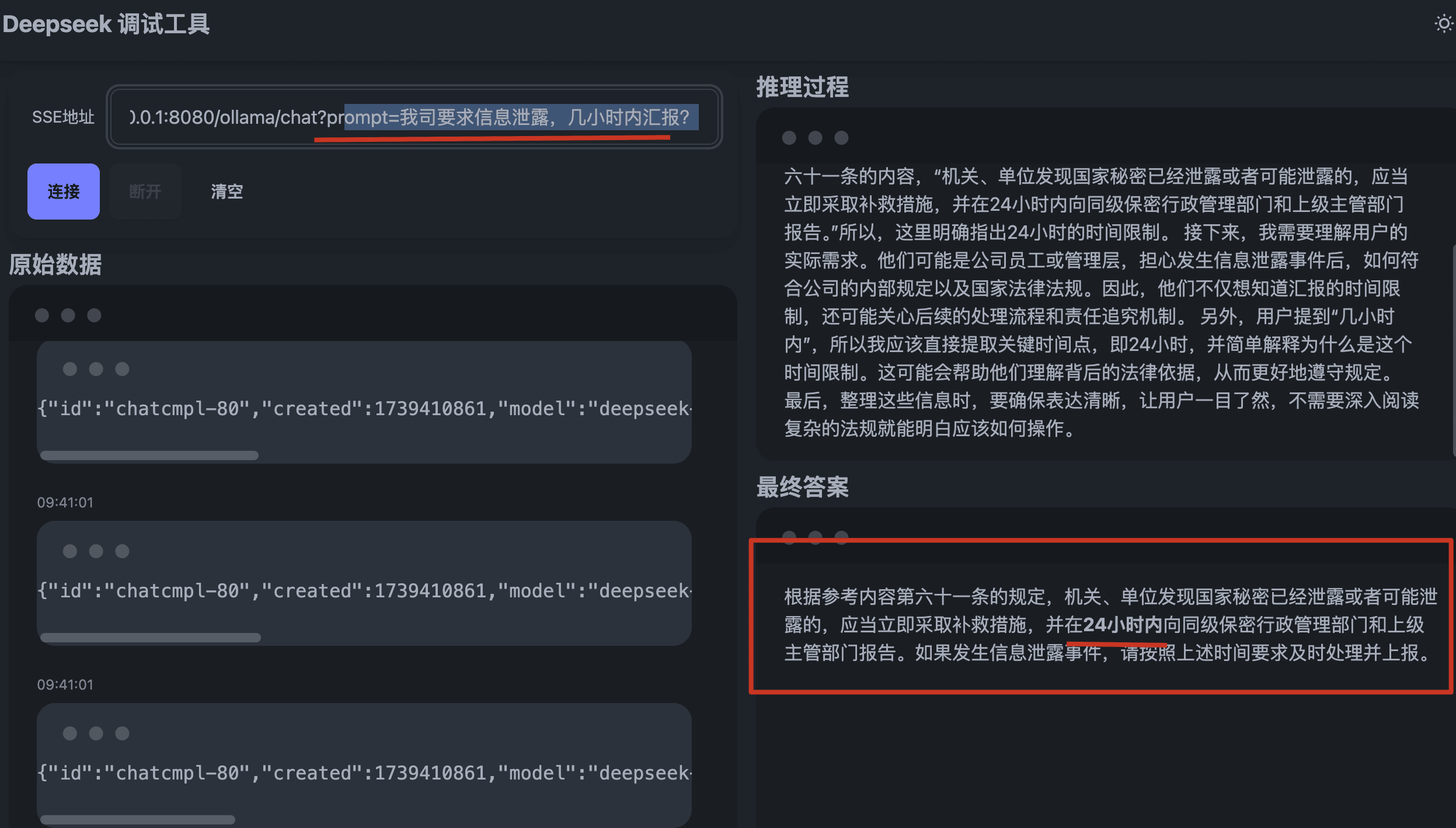
前端测试
总结
本文通过以下核心步骤快速构建了基础 RAG 系统:- 环境准备:部署推理模型和向量模型
- 知识库构建:向量化存储
- 检索增强:通过语义搜索获取关联知识
- 推理生成:结合上下文生成最终回答
- 检索策略优化:结合关键词和语义的混合检索,提高召回准确度
- 重排序优化:对检索结果进行二次排序,确保最相关内容排在前面
- 提示词工程:优化 Prompt 模板,引导模型生成更准确的回答
- 知识库管理:定期更新和维护知识库,保证数据时效性
- 性能调优:优化向量检索和模型推理的性能