- Qwen3 是全球最强开源模型,性能全面超越 DeepSeek R1,国内第一个敢说全面超越 R1 的模型,之前都是比肩
- Qwen3 是国内首个混合推理模型,复杂答案深度思考,简单答案直接秒回,自动切换,提升智力+节省算力双向奔赴
- 模型部署要求大幅降低,旗舰模型仅需4张H20就能本地部署,部署成本估算下来是能比R1下降超6成
- Agent 能力大幅提升,原生支持 MCP 协议,提升了代码能力,国内的 Agent 工具都在等它
- 支持119种语言和方言,包括爪哇语、海地语等地方性语言,全世界都可以用上 AI
- 训练数据 36 万亿 token,相比 Qwen2.5 直接翻倍,不仅从网络抓取内容,还大量提取 PDF 的内容、大量合成代码片段
- 模型部署要求大幅降低,旗舰模型仅需4张H20就能本地部署,是 R1 的三分之一

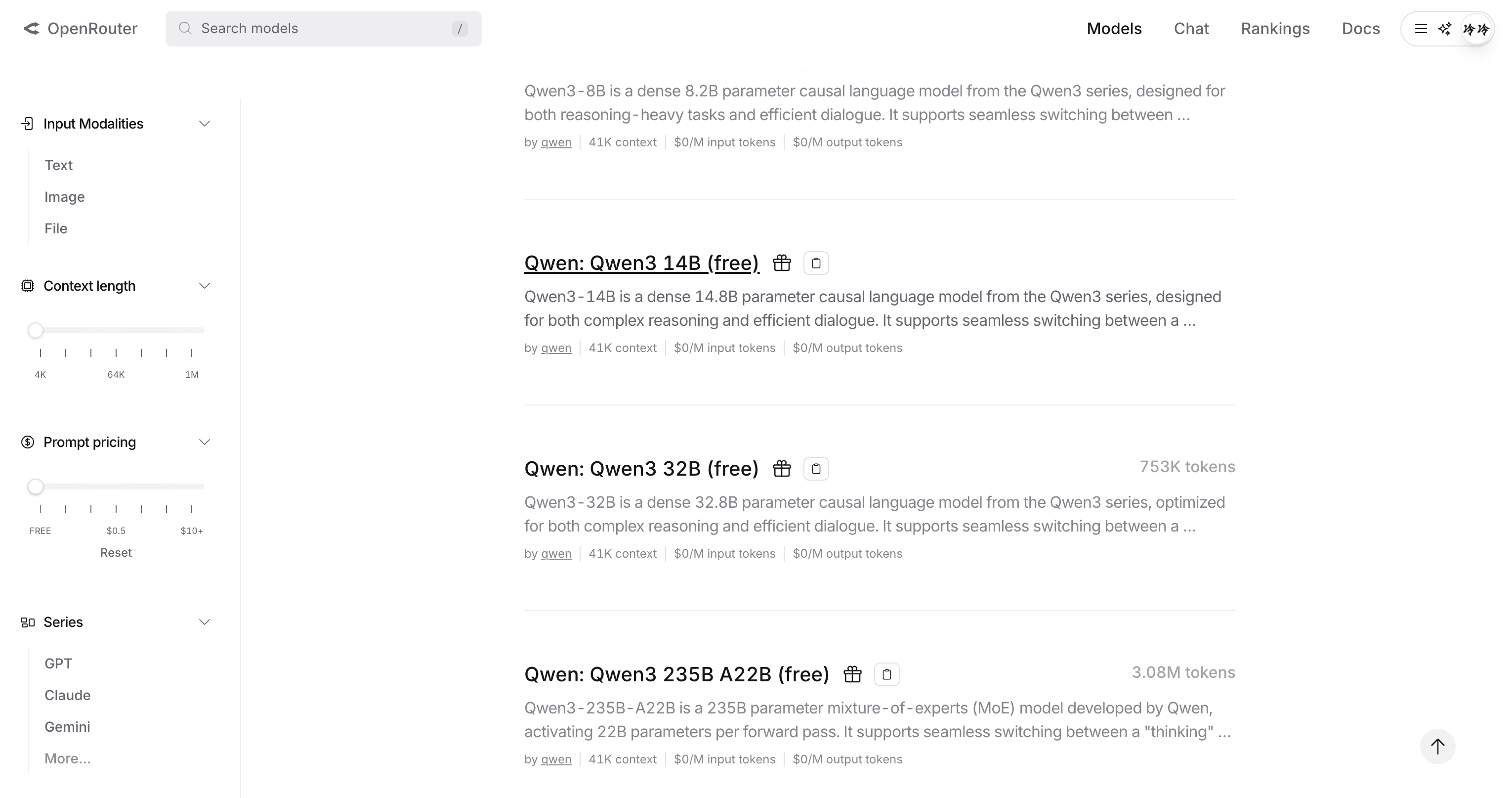
openrouter 满血版免费使用
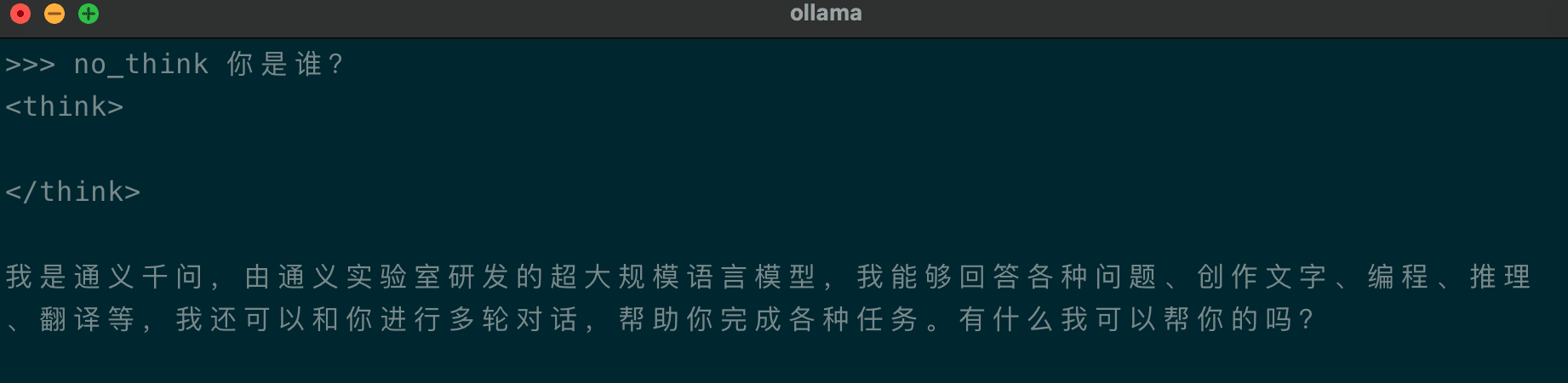
 提供了一种软切换机制,允许用户在 enable_thinking=True 时动态控制模型的行为。具体来说,您可以在用户提示或系统消息中添加 /think 和 /no_think 来逐轮切换模型的思考模式。在多轮对话中,模型会遵循最近的指令。以下是一个多轮对话的示例:
提供了一种软切换机制,允许用户在 enable_thinking=True 时动态控制模型的行为。具体来说,您可以在用户提示或系统消息中添加 /think 和 /no_think 来逐轮切换模型的思考模式。在多轮对话中,模型会遵循最近的指令。以下是一个多轮对话的示例:
推理模式

非推理模式
 全世界等了一个月,Qwen3 它终于来了!
全世界等了一个月,Qwen3 它终于来了!
模型特色:思考更深,速度更快
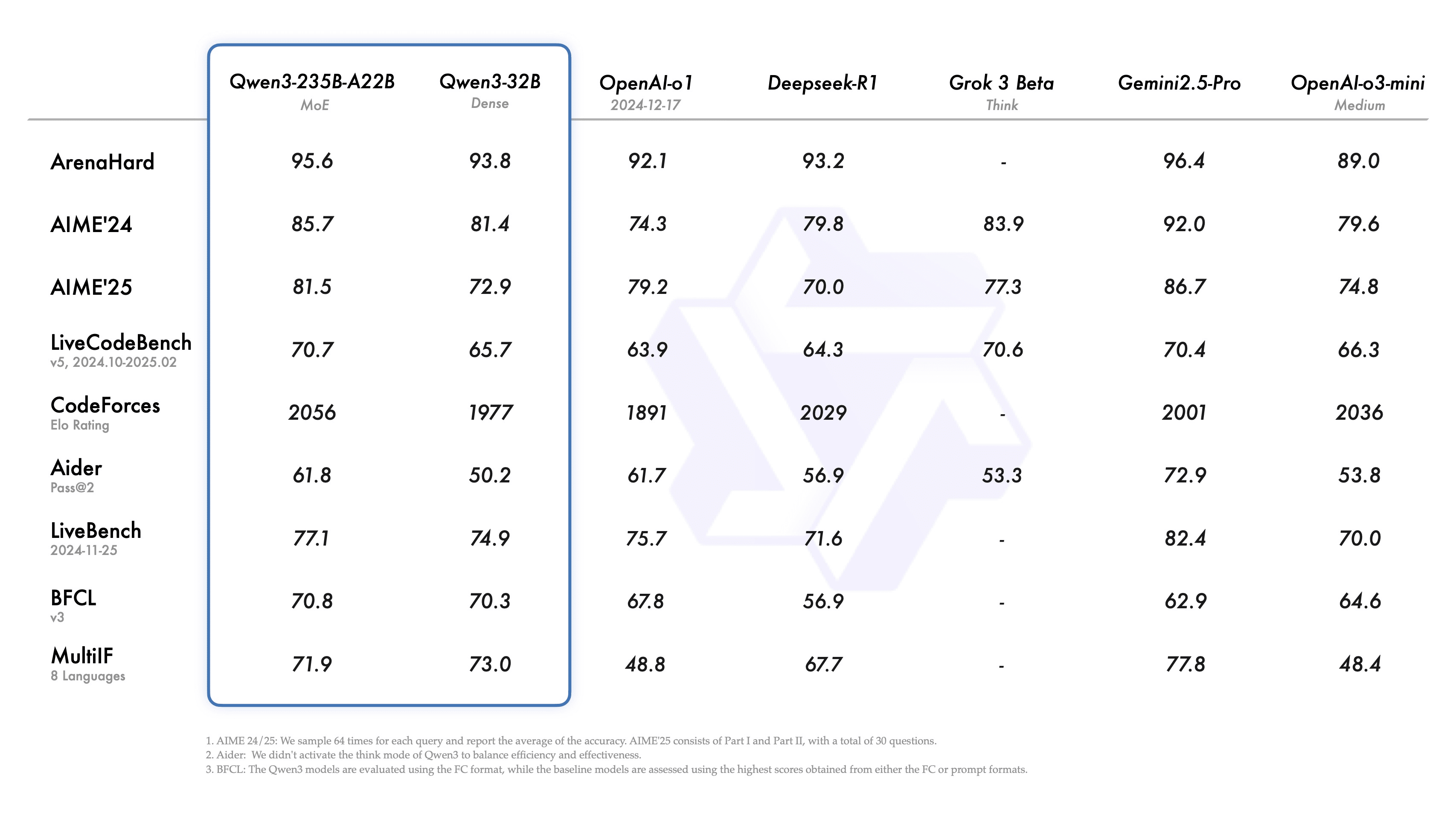
- Qwen3 是全球最强开源模型之一,其旗舰模型 Qwen3-235B-A22B 在编码、数学、通用能力等基准评估中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,取得了具有竞争力的结果。
- 小型 MoE 模型 Qwen3-30B-A3B 的性能优于 QwQ-32B,而激活参数仅为其十分之一;即使是像 Qwen3-4B 这样的小型模型,也能与 Qwen2.5-72B-Instruct 的性能相媲美。
- 独特支持在单一模型内无缝切换**“思考模式”(用于复杂逻辑推理、数学和编码)和”非思考模式”**(用于高效通用对话),确保在各种场景下都能获得最佳性能。(您可以在用户提示或系统消息中添加
/think和/no_think来逐轮切换) - 推理能力显著增强,在数学、代码生成和常识逻辑推理方面超越了之前的 QwQ(思考模式)和 Qwen2.5 instruct 模型(非思考模式)。
- 优越的人类偏好对齐,在创意写作、角色扮演、多轮对话和指令遵循方面表现出色,提供更自然、引人入胜和沉浸式的对话体验。
- 卓越的 Agent 能力,能够在思考和非思考模式下精确集成外部工具,并在复杂的基于 Agent 的任务中达到开源模型的领先水平。原生支持 MCP 协议。
- 支持 100+ 种语言和方言 (官方文档数据,实际宣称119种),具有强大的多语言指令遵循和翻译能力。包括爪哇语、海地语等地方性语言,全世界都可以用上 AI
- 训练数据 36 万亿 token,相比 Qwen2.5 直接翻倍,不仅从网络抓取内容,还大量提取 PDF 的内容、大量合成代码片段
- 模型部署要求大幅降低,旗舰模型仅需4张H20就能本地部署,是 R1 的三分之一
模型列表与运行
运行这些模型需要 Ollama 0.6.6 或更高版本。openrouter 满血版免费使用
推理模式
提供了一种软切换机制,允许用户在 enable_thinking=True 时动态控制模型的行为。具体来说,您可以在用户提示或系统消息中添加 /think 和 /no_think 来逐轮切换模型的思考模式。在多轮对话中,模型会遵循最近的指令。
非推理模式